
Welcome back! I previously described how I scraped the baking forum The Fresh Loaf, where people post their bread recipes, to get data to train a neural network to generate new bread recipes. I also detailed how I explored the data. In this post, I explain how I used some unsupervised learning techniques in the Natural Language Processing toolkit to further understand the textual data. Note: all the code I used for this project is in this repo.

Topic modeling
I knew the recipe data is unstructured and so I was curious if I could somehow create labels using statistical techniques. This is how I came across topic modeling, an unsupervised machine learning model to identify clusters of related words, and I thought maybe it could help make assign different topics to collections of recipes. Upon reading more, I found out about Latent Dirichlet allocation (LDA), a statistical model that uses a collection of documents, words and topics to learn which document belongs to which topic and what words describe that topic. This seemed like a great way to analyze the recipes I had to see if they fall under broad clusters that are distinct from each other. Using the count vectorizer from the scikit-learn toolkit to transform the words into numerical features, I applied LDA to fit the data to a defined number of topics and words describing them.
number_topics = 5
number_words = 15
count_vectorizer = CountVectorizer(max_df=1.0, min_df=2, stop_words='english')
count_data = count_vectorizer.fit_transform(df_recipe['Cleaned Recipe'])
lda = LDA(n_components=number_topics, n_jobs=-1, learning_method='batch',
max_iter=50, random_state=42)
lda.fit(count_data)
print('Topics found via LDA:')
print_topic_top_words(lda, count_vectorizer, number_words)Code language: Python (python)I played around with these parameters to see how the resulting topics changed, but generally too many words or topics led to overlap between topics, so I ended up choosing 5 topics and 15 words to examine the clusters. Looking at these below, Topics 0 and 1 are related to the fermentation process, with words like ‘hydration’, ‘hours’, ‘rest’ and ‘mix’, amongst others. Topic 2 is just general bread words. Topic 3 includes words related to baking process and Topic 4 seems to be about different ingredients and shapes (‘pizza’, ‘cheese’, ‘sugar’). I also used the pyLDAvis package to visualize these topics by doing dimensionality reduction using the t-distributed stochastic neighbor embedding (t-SNE) algorithm. In these two reduced dimensions, the topics seem to be well-separated, at least past the top words for the first two topics.
Topics found via LDA:
Topic #:0
flour dough water levain bread hydration crumb loaf time
hours salt rye bake loaves starter
Topic #:1
dough minutes let flour hours water oven mix temperature
bowl bake place add rest bread
Topic #:2
bread loaf baking recipe sourdough flour time im good make
like oven yeast dough ive
Topic #:3
water thermal heat baking energy process temperature density
things like know specific moisture cake bakers
Topic #:4
bread like time dough make pizza butter cheese breads flavor
used baked sugar crust sourdoughCode language: CSS (css)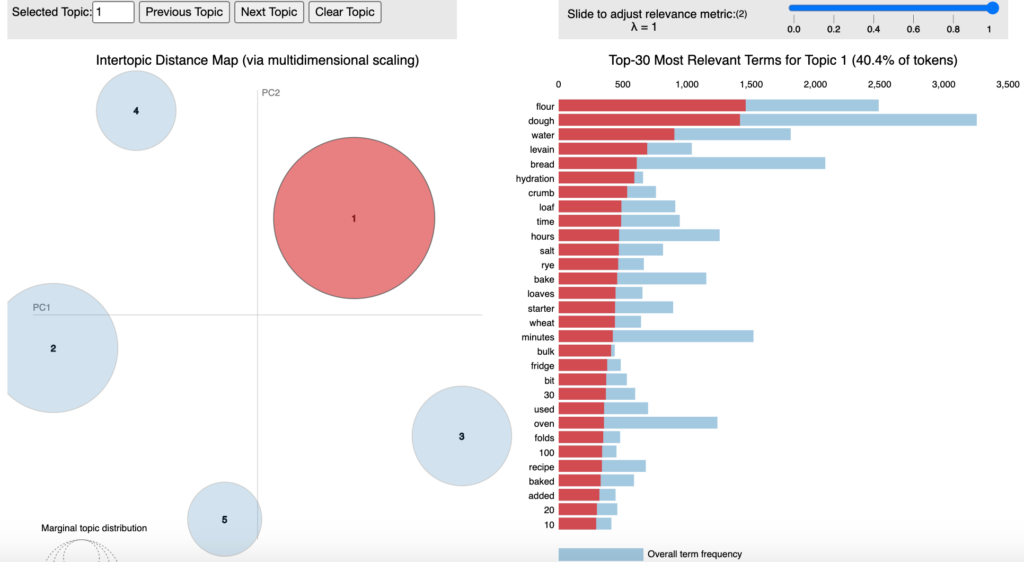
However, according to my domain knowledge as a baker, it’s a stretch to call these topics different, as there’s overlap between them and most recipes contain some or all of these topics in their texts. So I wanted to see if another topic modeling approach, Non-negative Matrix Factorization (NMF) would be better. This approach uses tf-idf vectorized representations to create matrices relating the number of words, topics and documents.
tfidf_vectorizer = TfidfVectorizer(max_df=1.0, min_df=2, stop_words='english')
doc_term_matrix = tfidf_vectorizer.fit_transform(df_recipe['Cleaned Recipe'])
nmf = NMF(n_components=number_topics, random_state=42)
nmf.fit(doc_term_matrix)
print('Topics found via NMF:')
print_topic_top_words(nmf, tfidf_vectorizer, number_words)Code language: Python (python)Keeping the same number of words and topics (15 and 5, respectively), I obtained the topics shown below with NMF. These topics are definitely different from LDA! The first topic seems to be general bread words again, but Topic 1 is fermentation process-related. Topic 2 describes ingredients used in recipes and Topic 3 and 4 are also time and process-related. Again, based on my domain expertise, I would not say these are well-differentiated topics but it is interesting to see new ways to cluster the data using the NMF algorithm.
Topics found via NMF:
Topic #:0
bread sourdough recipe like time im baking dough loaf think
ive good make crumb breads
Topic #:1
let dough hours minutes temperature pan bowl degrees sit
refrigerator remove place oven steam covered
Topic #:2
berries flour levain rye 50 day recipe seeds water extraction
loaves kamut unbleached wheat spelt
Topic #:3
flour pm water minutes min hours dough starter salt loaf hydration
bulk folds 30 10
Topic #:4
dough minutes place counter let flour seam rounds speed mix cover
add pull water middleCode language: CSS (css)Alright, that’s it with the unsupervised learning. My goal was to see if I could use it to assign labels to the recipes, but overlap between different topics prevented this. In the next post, I’ll write about how I built a couple language models to predict new bread recipes 🙂
