
In 2017, a friend gave me some sourdough starter to make bread with, and ever since then, my life has changed. It sounds cheesy, but I discovered a hobby that has led me to buy almost 200 pounds of flour at a time (seriously), develop a biweekly pizza baking habit, and dream of what bread I’m going to make in the coming days!
Because I spend a lot of time baking sourdough and experimenting with new formulas, I wanted to see if I could create an artificial intelligence-powered recipe generator that would predict something for me to make! One of my go-to websites for technique, tips and tricks has been the helpful bread baking forum, The Fresh Loaf, where people ask questions and post recipes. My idea was to scrape this website and get data to train a neural network to generate new bread recipes – and that’s what I did. At the end of this project, I was able to achieve my goal: to bake a machine learning-inspired loaf of bread, with ingredients predicted with a neural network.
Since there are multiple components to this project, I am breaking them down in a few blog posts. All the code I used for the project is in this repo.

Outline of the project
I followed the following steps during this project to obtain a recipe-generating model:
- First I scraped the Fresh Loaf website to get a list of recipes, cleaning and visualizing it to understand the trends in the dataset (Part I – what you’re reading right now)
- Then I explored the data using NLP tools to to gain further insight into what people on the blog are saying in their posts (Part II)
- Lastly, I trained a neural network to learn a word-based language model and generated sentences from it to get new recipes (Part III)
In this post, I’ll be describing the data collection and data exploration parts of the project.
Scraping the website to get data
I used the urllib library in python to query the website for webpages and Beautiful Soup to parse the HTML code. Inspecting the source code for blog posts on The Fresh Loaf, I realized that the ones containing recipes had the class node-type-blog, while other posts had other classes like node-type-forum; so I made sure to only grab pages with the former class. Then I had to identify where the body of the blog containing the text was. The tags had a lot of nesting, and to me, were a little bit of a mess, since I don’t look at HTML code very often. The <div> elements of this class contained both the blog text as well as the comments and ads, but I only wanted to isolate the recipe. So I decided to use the prettify() function in Beautiful Soup and examine the resulting string to see where the body of the text was.
import urllib.request as urlib
from bs4 import BeautifulSoup
def get_recipe(page_idx):
try:
page_url = f'http://www.thefreshloaf.com/node/{page_idx}'
page = urlib.urlopen(page_url)
soup = BeautifulSoup(page, 'html.parser')
# only process pages that are blog posts, aka contain recipes
if 'node-type-blog' in soup.body['class']:
print(f'blog at index {page_idx}')
soup = soup.prettify()
soup = soup[soup.find('title'):]
soup = soup[soup.find('content="')+len('content="'):]
end = soup.find('"')
return preprocess(soup[:end])
except Exception:
print(f'Page: http://www.thefreshloaf.com/node/{page_idx} not found!')Code language: Python (python)The tags in this string made it quite easy to find the recipe body (contained in the content section) and after isolating that string, I used a quick preprocessing function to get rid of any HTML remnants that ended up in the recipe’s text.
def preprocess(text):
text = text.replace(u'<br/>', '')
text = text.replace('(<a).*(>).*(</a>)', '')
text = text.replace('(&)', '')
text = text.replace('(>)', '')
text = text.replace('(<)', '')
text = text.replace(u'\xa0', ' ')
return textCode language: Python (python)I scraped ~10000 posts to end up with 1257 recipes that I collected into a text document, each separated by a new line. I could keep scraping for more but the website stopped responding after querying it for a few hours, so I decided to stop and understand the data from here.
Data cleaning and exploration
To begin, I loaded the text file into a Jupyter notebook and calculated the length and unique words in each recipe. Upon inspecting the data, I found that a lot of authors referred to other url’s where they obtained inspiration for their recipe and I removed these “words” from the text. I also tokenized the recipe by removing stop words using the NLTK corpus. However, a lot of authors describe their own thoughts and procedures so removing the stop words “i” and “me” would lead to grammatical issues while training a language model; I retained these stop words in the text.
def tokenize(text):
punctuation_map = str.maketrans('', '', string.punctuation)
stopwords_list = stopwords.words('english')
stopwords_list.remove('i')
stopwords_list.remove('me')
stopwords_list.append('com')
stopwords_set = set(stopwords_list)
text = text.split()
# remove website links in text
text = [word for word in text if not ('http' in word or 'www' in word)]
text = [word.translate(punctuation_map).lower() for word in text]
tokenized_words = [word for word in text if word not in stopwords_set]
return tokenized_wordsCode language: Python (python)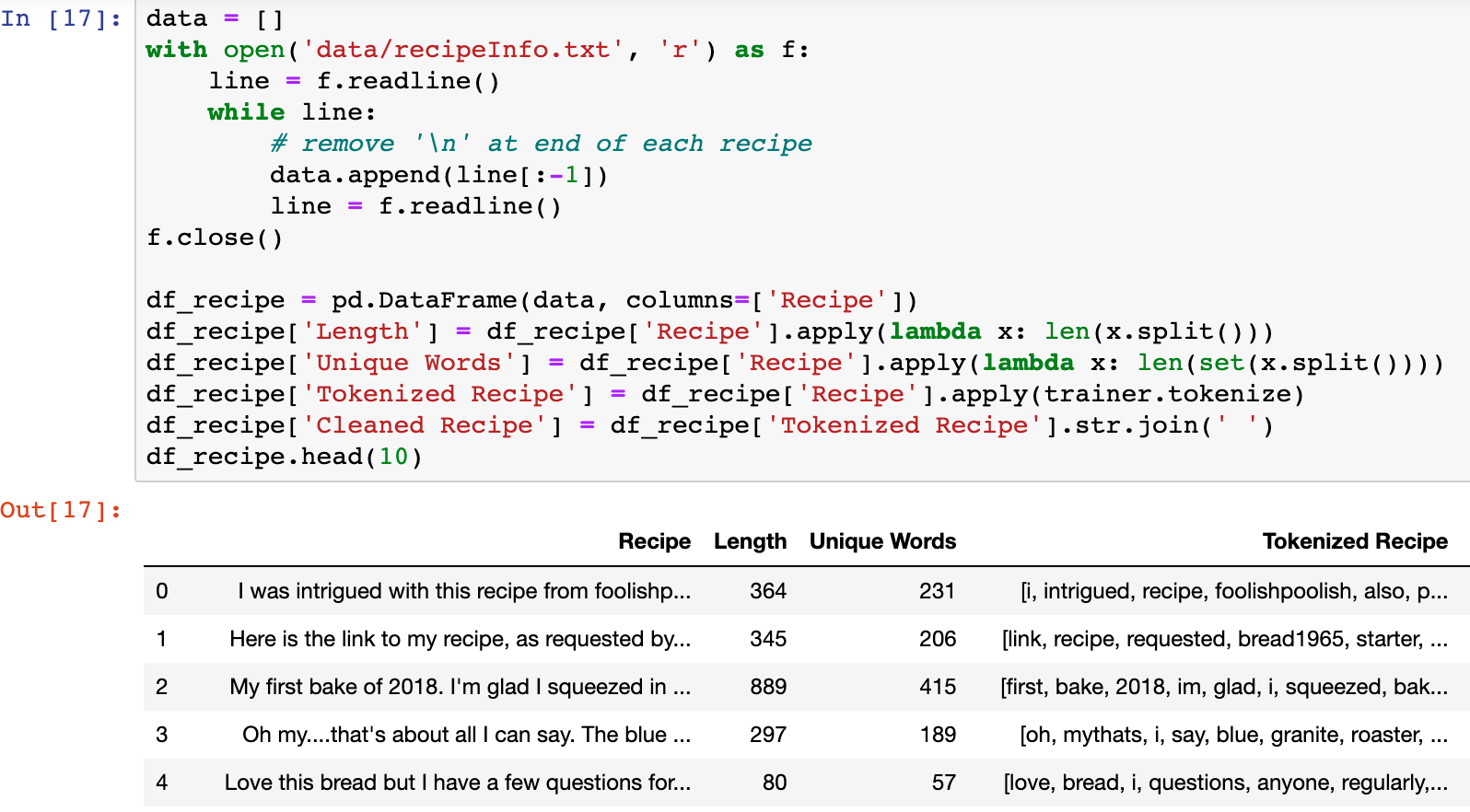
The recipes have an average length of 294 words with a standard deviation of 618. That’s quite a variation in recipe lengths! They also contain 166 unique words on average, again with a high standard deviation of 174 words. This high standard deviation indicates a large tail, and indeed, upon examining the data, I found a few recipes with over 1200 words that are skewing these statistics. One post even has >20000 words!
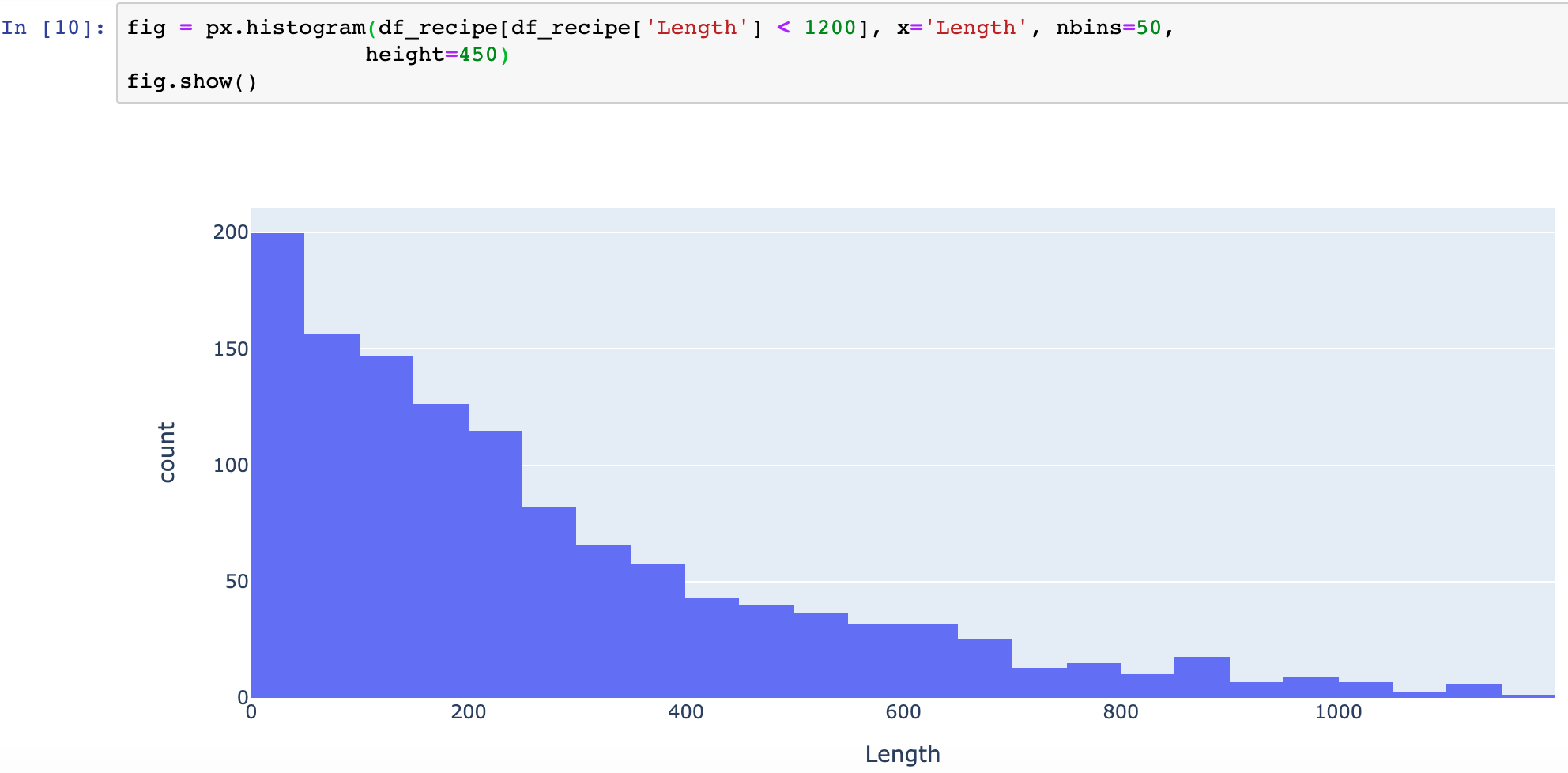
Looking at the histogram of the length of recipes with less than 1200 words, I found that most contain 0 – 400 words. There are 47 recipes with less than 10 words, and these are usually ones where people post a link to something interesting or post a picture with a one-line description.
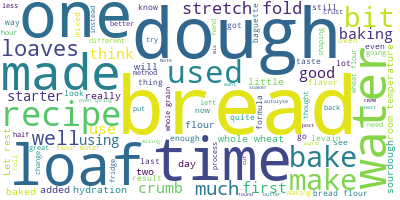
To get a visual representation of what the texts of these recipes contain, I created a word cloud based on the words in the recipes. This package creates an image of the top terms after removing stop words. As suspected, the most common words are ‘bread’, ‘dough’, ‘loaf’, ‘time’ and ‘water’. Some of the other words that pop out to me are ‘stretch’, ‘fold’ and ‘starter’. From my experience baking bread, time is an important ingredient, and it checks out that it’s quite a frequent word. I’m also happy to see stretch and fold there, as this is a common technique to develop strength in the dough and lots of people seem to use it! It’s surprising that starter shows up but the word ‘yeast’ does not, as bread can be leavened using both a wild-yeast starter as well as standard commercial baking yeast. It seems as though the users of The Fresh Loaf, like me, prefer using sourdough starters to make their bread rise and coax out fun flavor profiles due to its wild nature.
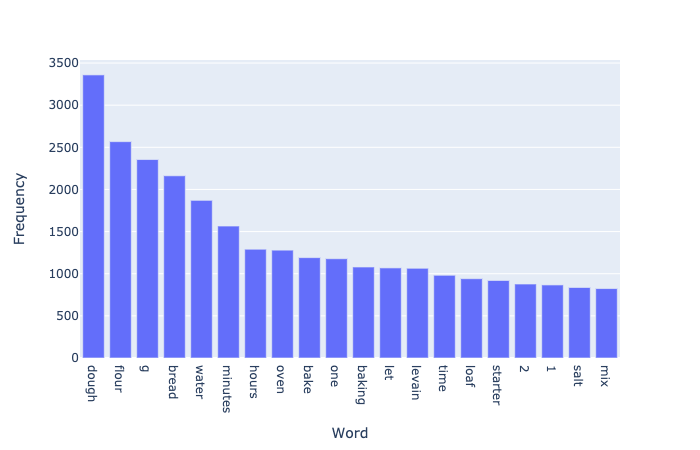
More quantitatively, I made a long list of all the words and counted the number of times each one occurred to plot the 20 most common words occurring in the recipes. As with the word cloud above, we see ‘dough’, ‘flour’, ‘water’ and units of time in this list of frequently used terms.
Phew – that’s a lot of stuff! Here’s some carbs and sugar to load up on before part II 🙂
